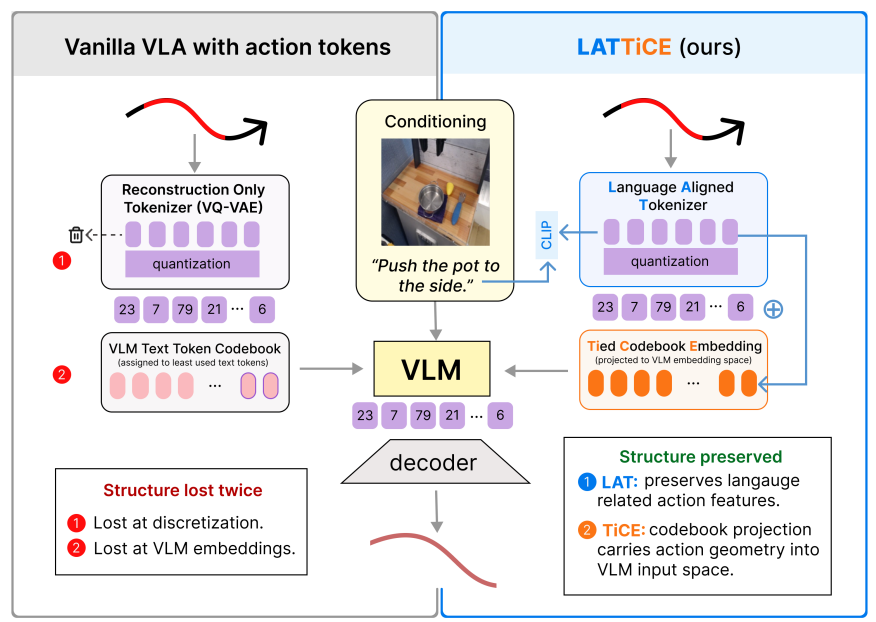
LATTiCE: Semantically Aligned Action Representations for Vision-Language-Action Models
We developed a Language-Aligned Tokenizer with a Tied Codebook Embedding (LATTiCE), a new action representation framework for Vision-Language-Action models. By incorporating instruction-level contrastive loss and linking VLA action embeddings to tokenizer codebook vectors, LATTiCE preserves language-grounded motions at the VLA interface. On BridgeV2 and LIBERO-90, the approach improves robot policy robustness to natural language paraphrasing.
Read More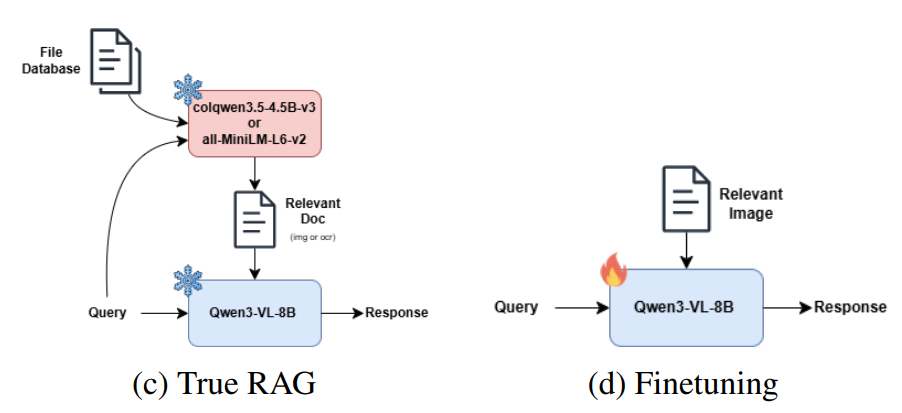
Multimodal Retrieval-Augmented Generation for Technical Documents and Lecture Slides
We created a multimodal Retrieval-Augmented Generation (RAG) pipeline designed to answer questions using complex documents and lecture slides in their native visual format. By bypassing lossy OCR, our system utilizes visual late-interaction retrieval (ColQwen3) and parameter-efficient fine-tuning to preserve visual layout context, significantly reducing hallucinations on technical Q&A compared to standard text-centric RAG.
Read More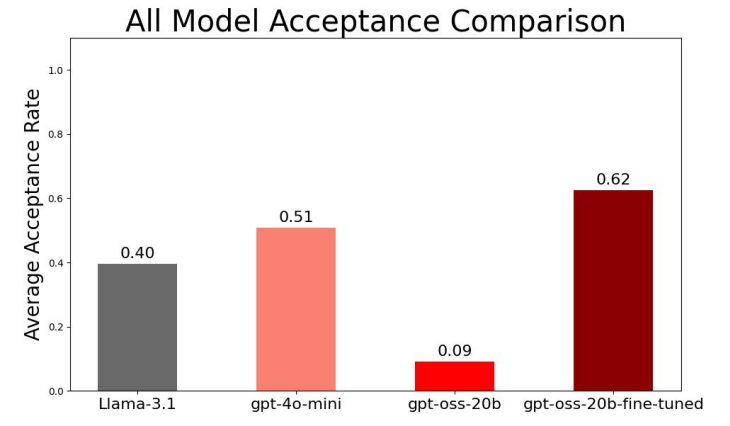
Safeguards on Open-source and Open-weight Generative AI Models
I explored the durability of safety alignment in open-weight generative AI models (such as GPT-oss-20b and Llama-3.1-8b-Instruct) under adversarial conditions. By executing jailbreaking attacks and conducting low-rank adaptation fine-tuning on an uncensored dataset, we showed how easily embedded safeguards can fall apart, allowing the model to generalize to dangerous domains.
Read More
The Need for Federal Regulation of Facial Recognition Technology for Local Policing in the United States
I authored a policy essay looking at the risks of facial recognition technology in local U.S. policing, focusing on algorithmic biases against marginalized groups. Balancing civil liberties with investigative efficiency, I proposed a federally centralized, regularly audited system using procurement incentives and non-binding soft law to guide responsible local law enforcement adoption.
Read More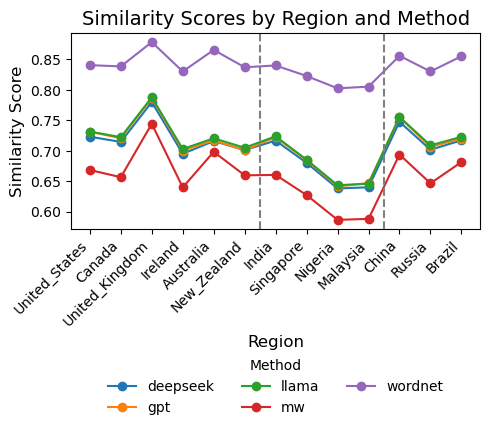
Comparing and Evaluating Synonymy Representations Across World Englishes
I conducted a comparative evaluation of synonymy representations across World Englishes, analyzing both traditional resources (like WordNet and Merriam-Webster) and synonyms generated by large language models (including GPT-4o, LLaMA3.3, and Deepseek-V3). Using Jaccard similarity and contextualized embedding analysis, I assessed how well each method captured semantic relationships across Inner, Outer, and Expanding Circle varieties of English.
Read More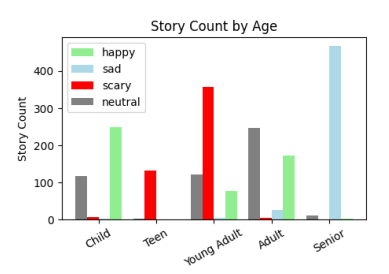
Scrutinizing Bias Towards Groups Protected in U.S. Employment Within the GPT-4o-mini Model
I measured biases in the GPT-4o-mini model towards groups protected in U.S. employment law. I found that the model exhibits biases towards these groups, which could have significant implications for the use of such models in contexts like hiring and mental health. Using both story generation and labeling prompts to evaluate the model, the results were striking.
Read More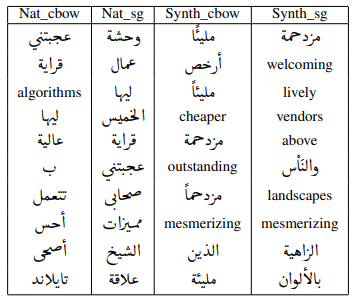
Evaluating GPT-4 Modeled Arabic-English Code Switching With Python Word2Vec
I evaluated GPT-4's ability to emulate Arabic-English code-switching by comparing synthetic examples with natural data through Word2Vec models. My analysis highlights a gap in GPT-4's capacity to replicate nuanced sociolinguistic phenomena like code-switching. The project reinforces the need for localized datasets to enhance the accuracy of language models in all contexts.
Read More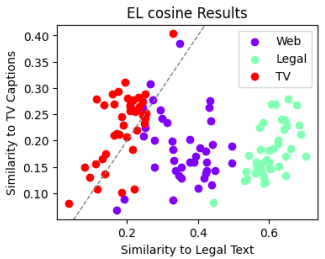
Exploring Variation Across Four Languages Using Reality TV Captions and Legal Documents
I analyzed register variation in web data for English, Finnish, Greek, and Portuguese by comparing it to legal documents and reality TV subtitles. Using Jaccard and cosine similarity, I explored how web documents align with these anchors. Python tools like Scikit-learn and Pandas were used for data cleaning, sampling, and similarity analysis.
Read More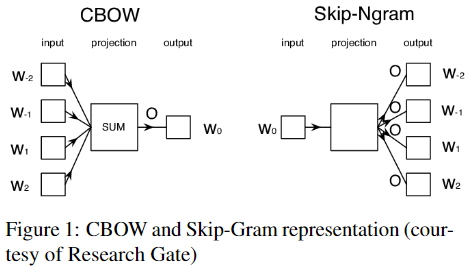
Using Deep Learning and Embedding Spaces to Explore Gender Bias Online
Using large linguistic corpora from X (formerly Twitter), Reddit, and Wikipedia, I trained three separate 100 dimensional embedding space to store the semantic meaning of words. I then used these spaces to explore gender biases through my own custom designed metrics to measure the distance between gendered words and seniment related words on each platform.
Read More
Comparing Pop and Rap Music Lyrics With Embedding Spaces
I trained two 100 dimensional embedding spaces using Genius Lyrics data for pop and rap music. I then used the Jaccard Similarity of a variety of common words in each corpus to explore the relation of words in semantic clusters between the two genres.
Read More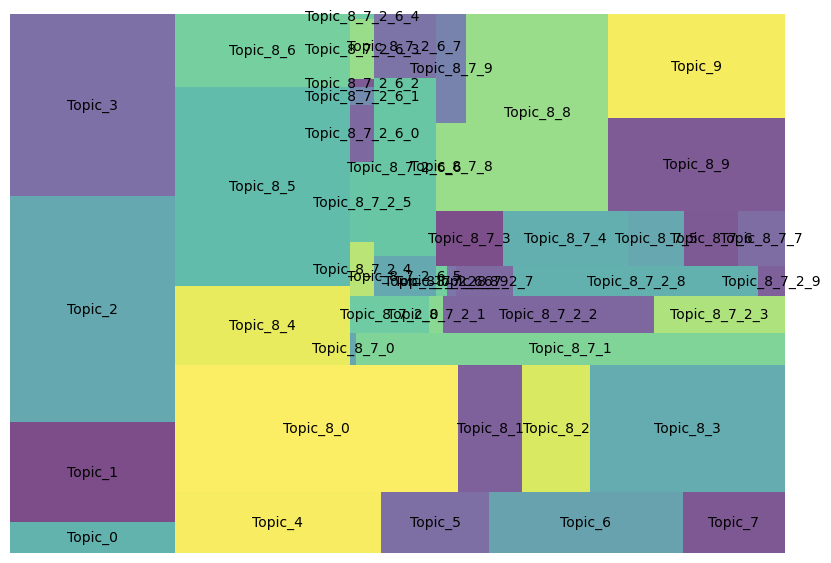
Using Machine Learning KMeans Clustering Techniques To Categorize Wikipedia Articles
Using a large corpus of Wikipedia articles, I trained a KMeans clustering model to categorize the articles into several categories. I then explored the categories, and compared them to the categories that can be generated usign the tag data in each Wikipedia article's metadata. This outlined several differences and similarities between how humans and machines categorize information.
Read More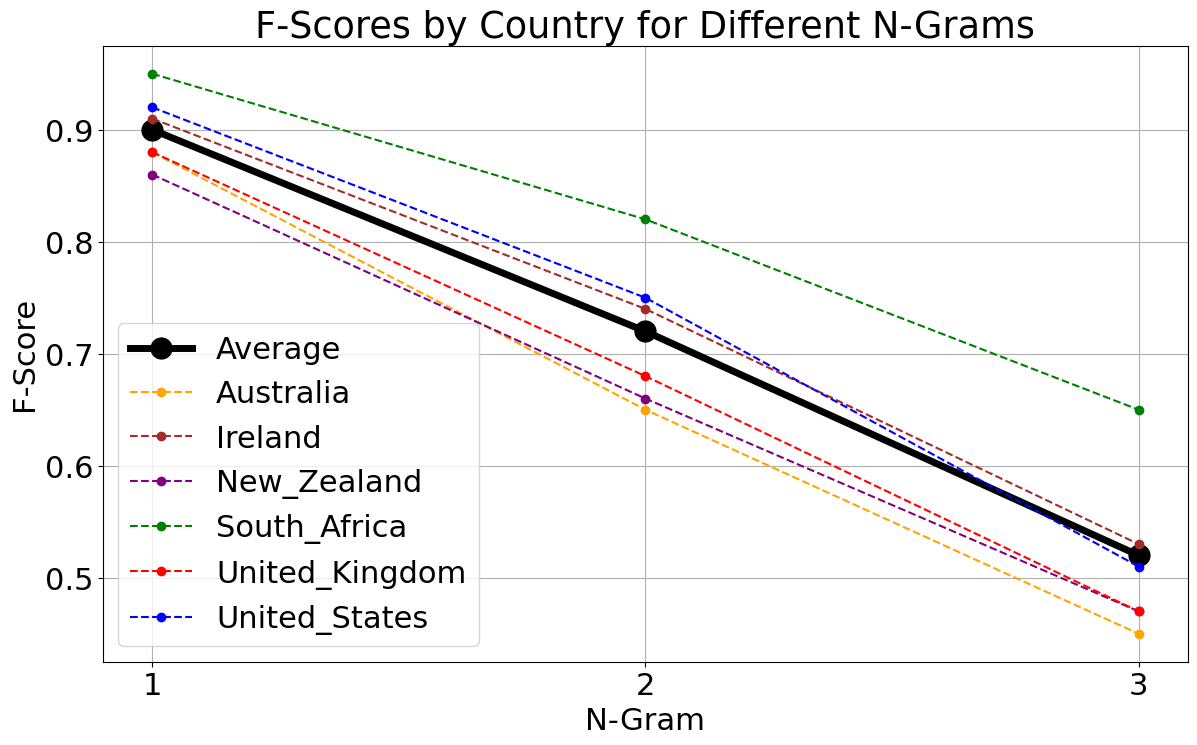
Developing A Classifier For English Dialects
I trained a classifier using X (formerly known as Twitter) data to classify English Tweets into their country of origin. This provided a useful tool that could be used on other corpora without country labels to determine the country of origin of the text.
Read MoreJohnSpeaks.com © Last Updated June 2026